Plan-Seq-Learn
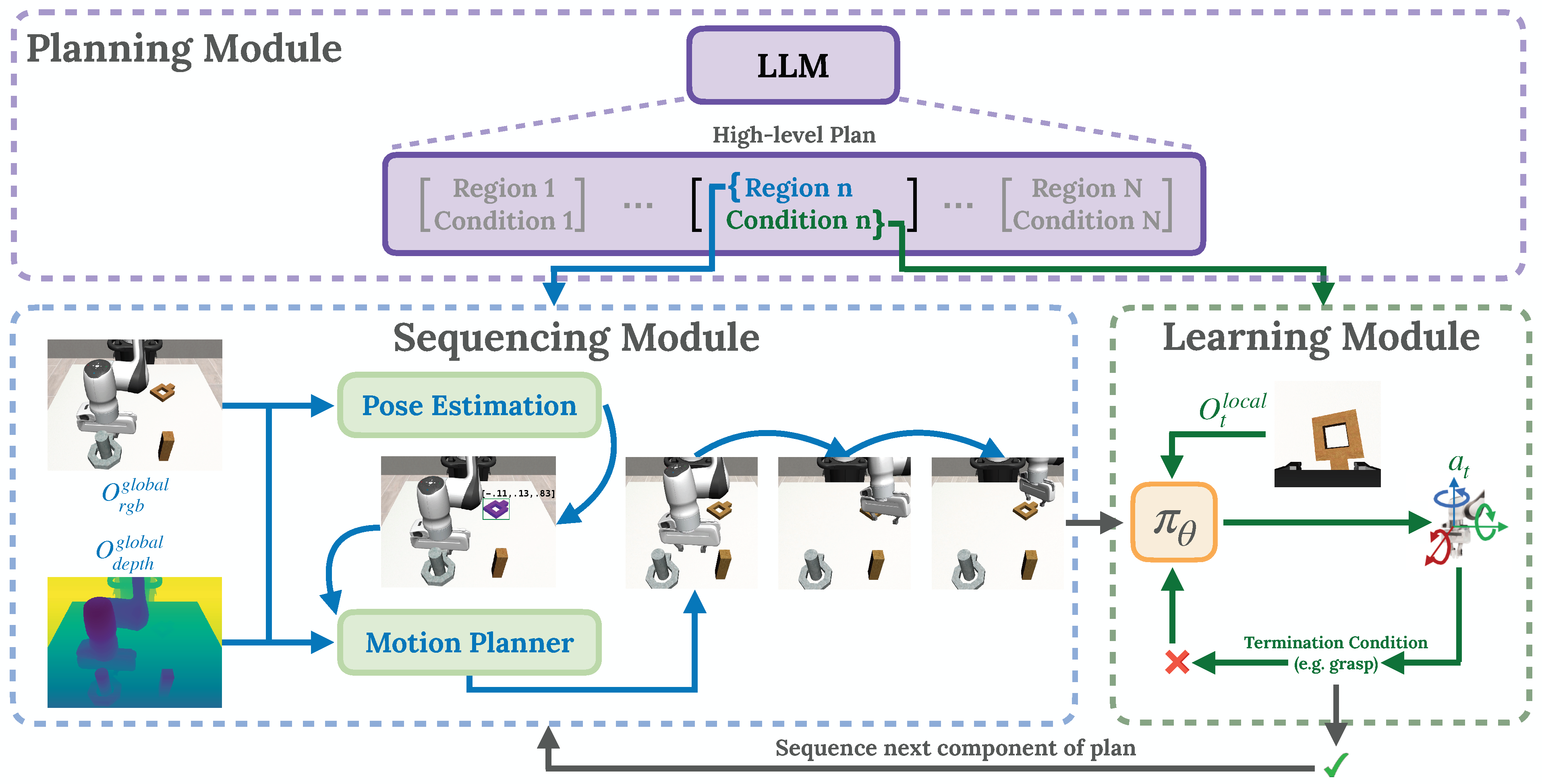
PSL decomposes tasks into a list of regions and stage termination conditions using an LLM (top), sequences the plan using motion planning (left) and learns control policies using RL (right).
PSL solves contact-rich, long-horizon manipulation tasks
RS-NutRound: 98%
RS-NutSquare: 97%
RS-NutAssembly: 96%
PSL enables visuomotor policies to learn pick-and-place behaviors with 4 stages
RS-CanBread: 90%
RS-CerealMilk: 85%
PSL efficiently solves tasks with obstructions by leveraging motion planning
OS-Push: 100%
OS-Lift: 100%
OS-Assembly: 100%
PSL solves long-horizon kitchen manipulation tasks with up to 5 stages.
K-Multistage-3: 100%
K-Multistage-4: 67%
K-Multistage-5: 67%
Extensive Emprical Evaluation
PSL solves 20+ long-horizon robotics tasks across four benchmark environment suites with greater than 80% success rates